
项目简介
比赛题目
网页短视频应用
使用七牛云存储、七牛视频相关产品(如视频截帧等)开发一款Web端短视频应用
基础功能(必须实现)
- 视频播放:播放、暂停、进度条拖拽
- 内容分类:视频内容分类页,如热门视频、体育频道
- 视频切换:可通过上下键翻看视频
高级功能(可选实现)
- 账户系统:用户可登录,收藏视频
- 可参考常见短视频应用自由增加功能,提升完善度,如点赞、分享、关注、搜索等
最终实现
Github地址:
- 项目:VideoUtopia
- 后端地址:VideoUtopia/utopia-back
- 前端地址:VideoUtopia/utopia-front
项目功能:
- 存储模块
- 使用七牛云kodo进行存储,存储 头像、封面、视频
- 支持视频预处理,自动截取封面,异步回调替换
- 用户模块
- 登录、注册、查看个人主页
- 视频模块
- 热门视频:根据三小时内点赞量动态替换
- 推荐视频:推送所关注用户发布的视频
- 上传视频
- 视频内容分类
- 交互模块
- 点赞、关注、收藏
- 查看自己曾收藏过的视频
- 查看自己关注的用户
详细介绍
项目大体来说中规中矩,这里介绍几个稍微有意思的点
存储模块
这里先吐槽一句,七牛云的文档写的有些粗糙
通过kodo存储对象,服务端下发 带回调、带数据处理、带自定义参数 的凭证,客户端根据凭证上传视频,上传成功后七牛云回调服务端,服务端处理数据。时序图如下:
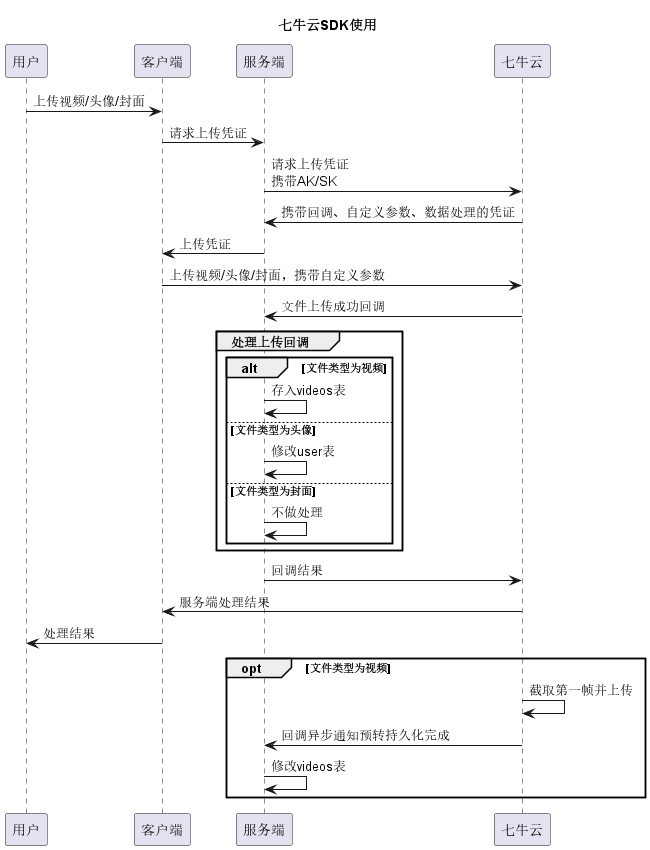
为保证访问密钥的安全性,采用服务端下发凭证的形式
上传文件主要集中于以下几个场景
- 上传/更换头像
- 上传视频
- 上传封面/七牛云自动截取封面
设计callback接口时,考虑到以下两方面
- 文件上传调用次数相对其它接口较少,且回调方处理数据任务量不大
- callback由七牛云调用,处理数据前会检测是否为七牛云发起
- 处理回调时,不同类型控制层代码相近
所以选择将三种类型全部集中于一个回调接口
在处理数据时,如上传视频时,需要知道上传用户、标题、视频类型等信息,需要客户端上传时,携带自定义参数,callbackBody定义如下:
1 | { |
服务端根据file_type判断上传类型(视频-携带封面/视频-不携带封面/封面/头像),不同文件类型对应不同的参数校验,并单独处理
- 封面:不做处理
- 视频-携带封面:插入视频
- 头像:修改user表
对于视频-不携带封面:
- 以用户头像做临时封面,插入视频
- 将视频key做键,值为视频id,存入redis,半小时过期时间
- 七牛云截取封面成功后,异步回调接口,根据视频key找到视频id,替换视频封面
服务端在注册上传凭证时,携带了预转持久化参数:vframe/jpg/offset/1|saveas/bucket:${etag}.jpg,七牛云会截取视频第一帧并持久化存储,在存储完成后,调用callback接口
callback在检测到请求中含有inputKey字段时,根据视频key从redis取出视频id,并替换视频封面
热门视频
需解决的问题
热门视频的选择体现在用户的点赞上,若只按照点赞数量排序,会出现以下问题:
- 点赞量高的视频堆积,更换频率较低,用户经常刷到重复视频
- 新发出的有潜力的视频得不到推荐,无人问津
因此,热门视频可采用 三小时内的点赞量 进行动态更换
另外当 突然更换热门视频榜单 时,用户当前观看热门视频位置无法记录,会推送曾经的视频,影响用户体验,这里下文会详细举例
设计思路
- 开启协程,每隔三个小时异步拉取DB,获得三个小时内点赞量最多的100个视频,将视频id存入redis的zset中
- 用户获取视频时,把三小时内点赞数从高到低返回给用户,一次返回20个,同时给出当前最小score,做下一次的分页依据
score设计
直接将三小时内的点赞数作为score:无法根据score进行区分点赞数相同的视频,只能考虑 重复推送 或 忽略此类其他视频 两种方案,显然均不合理
所以需要在score侧将视频区分开,因此最终选用 float(三小时内点赞数.视频id) 做score,确保热门视频不重复、不丢失
版本控制
对于更换热门视频导致用户体验下降的问题,我们采用版本控制的形式来解决
我们先看一个案例:
- redis异步拉取DB,获取前100个热门视频id,存入zset,我们记为版本A
- 两小时五十五分钟后,用户A分页刷取热门视频,获得版本A的前20个视频,并观看
- 五分钟后,redis异步拉取DB,更新zset
- 用户A获取下一分页视频
此时虽然用户能正常获取视频,但因zset的改变,用户A可能会刷取到一些重复的视频,导致体验下降
为解决该问题,我们进行了热门视频缓存版本控制,总共有A、B两个版本,每隔三小时轮换更新一个版本,服务器中记录当前最新版本,当用户新发起查询热门视频请求时,返回当前最新版本,用户查询时携带了版本信息,就使用该版本
下面我们来看些例子
- redis异步拉取DB,获取前100个热门视频id,存入zset,我们记为版本A,当前版本是A
- 用户A刷取热门视频,获得20个视频、nextScore、版本号A
- 三小时后,redis异步拉取DB,更换版本B中的热门视频,当前版本是B
- 用户A刷取热门视频,请求参数中携带版本号A -> 从版本A的zset中取出数据返回,用户体验无影响
- 用户B刷取热门视频,未携带版本号 -> 给出当前版本号B返回值,并从版本B中取数据
- 三小时后,redis异步拉取DB,更换版本A中的热门视频,当前版本是A
我们可以直观看出,从用户A获取版本A中的视频,到版本A中的热门视频变更,中间至少要间隔3个小时,这个时间差对业务而言完全可以接受
代码实现
异步更新,从DB中读取写入redis
1 | // 热门视频缓存 每隔三小时更新一次版本 |
从redis中分页获取当前热门视频
1 | // GetPopularVideo 获取当前热门视频 |
判断用户是否点赞
判断用户是否为该视频点过赞,查询量较大,有以下三种应对方式
- 不做缓存 -> DB压力较大
- 全量缓存 -> 随时间推移,缓存侧存储压力较大
- 部分缓存 -> 如何判断是否回源?
前两个基本是不能接受的,不予考虑。先说下结论,最终我们选择了下文的方案二
方案一:缓存过期不回源
对于部分缓存,判断何时回源是很重要的,若缓存过期时间很短,未查到缓存则接回源,那DB侧压力仍然很大
另一种方法是提高缓存时间,均不回源:
简单计算一下,如果设置30天过期时间,每天300万用户,每人点赞20个视频,假设一个是0.5kb 30*300按10000,10k*20*0.5kb,大约是100Mb
- 查询缓存成功:表示点过赞,返回true
- 查询缓存不成功:30天以前点过赞/没点过赞,不回源,直接返回false
DB存储点赞数据时,我们可以在uid与vid间添加唯一索引,插入数据使用insert on duplicate key update保证幂等
这个存储量,如果我们把时间过期时间拉到一年,其实也是可以接受的。但问题在于业务是否可以接受一年前点过赞的视频,再次打开时不显示点过赞。
并且因为要为不同的key设置不同过期时间,可以选用string和zset两种形式
- string形式:key分布较为分散,无法进行统一管理,较为不便
- zset形式:要过期的时间记为score,异步清除 - 实现较为麻烦
方案二:用户维度存储点赞视频,冷热数据分离冷数据回源
该方案参考了 得物 的点赞设计,设计较为巧妙,缓存结构如下:
like:15中15为用户uid,3454、723、645均为用户点过赞的视频vid,minVid是冷热数据的分界线,低于该值记为冷数据,ttl为过期时间
1 | { |
设计思路如下:
- 用户维度:判断是否点赞业务场景一般是:一个用户对应一堆视频,以用户维度创建缓存,可以大幅减少命令执行次数
- 冷热数据分离:视频id是自增的,id从大到小对应这上传时间从新到旧,用户刷到旧视频的频率相对较低,可根据视频id进行冷热数据分离
- 冷数据回源:冷数据回源查DB,并写入缓存,这样就可以保证缓存高效利用而且压力不过太大
- 冷热阈值:限制hash中的字段数,批量查询时,若发现字段数超过1500则查询结束后重构缓存,取前750个视频id,修改minVid
- ttl字段:以前每次查看是否要更新缓存时,都要调用TTL命令,执行命令次数翻倍,将TTL写入字段一同查询,可减少命令数
- 续期:当TTL临近过期(达到2/3时)进行续期
业务逻辑
批量获取用户是否点赞:
- HMGET获取vid1、vid2、vid3、ttl、minVid
- 获取失败:不存在该key,重新构建
- 获取成功但vid未找到
- vid >= minVid ==》未点赞
- vid < minVid ==》冷数据,回源查DB,并写入缓存
- 检查TTL快过期则续期
- 检测字段值是否超过阈值,超过则重建
- 返回结果
用户点赞:更新DB,HSET添加该字段,不存在则构建
用户删除:更新DB,HDEL删除该字段,不做其他处理
优点:
- 可高效利用缓存且缓存存储量不大
- DB回源的数据量可以接受
缺点:实现起来较为复杂
代码实现
这种缓存模式下需要关注:点赞、取消点赞、批量判断用户是否点赞
我们先实现基本的方法:
- 构建用户点赞视频缓存 - 相对简单,根据视频id和阈值HMSet即可,代码见
utopia-back\cache\like.go:190 - 判断数量是否超过阈值 - 查询字段数,和阈值去做判断
- 超出阈值重建缓存
超出阈值重建缓存时,其中一半的字段是可以保留的,删除不需要的即可
- 先取出所有字段,排序后将minVid设置为第750位的vid
- 调用 构建用户点赞视频缓存 函数,不需要传视频id,通过该函数刷新ttl与minVid即可
- 调用HMDel删除剩余字段
实现代码见utopia-back\cache\like.go:271
在utopia-back\cache\like.go:271将 用户点赞视频批量写入缓存 进行封装,用户点赞时进行调用。
判断用户是否批量为视频点赞时,检查ttl与字段数量,需要则调用方法进行重建:
1 | // utopia-back\cache\like.go:138 |
接口及IP限流
采用 令牌桶 对可针对不同接口配置不同的限流策略,同时支持对用户IP限流,防止用户恶意攻击
通过github.com/juju/ratelimit实现令牌桶,将接口做map的key,对应不同的*BucketConf,BucketConf包含一个Bucket,用于对接口进行限流,接口限流支持阻塞等待,配置maxWait
每隔BucketConf配置一个map[string]*ratelimit.Bucket,用于对IP进行限流,IP限流不支持阻塞等待,达到阈值时直接阻止该请求。
1 | var BucketMap = make(map[string]*BucketConf) |
限流中间件初始化,对不同接口和对不同接口下的IP配置不同的限流策略
1 | // InitRateLimit 注册限流 |
将代码注册到路由中间件,当请求失败时报错请求频繁。
1 | // 代码注册到路由中间件 |
待改进
七牛云存储 kodo 自定义变量直接使用用户id
七牛云回调不支持自定义header,所以直接在自定义变量中传递的用户id来判断身份,这块肯定是不安全的,用户找到对应接口后,完全可以自己尝试去替换别人的头像或给别人上传视频。自定义变量应改为用户自身token,服务端单独鉴权
用户 点赞/取消点赞 时,直接写入
like_counts表
此处具有较大的优化空间,倘若每次点赞都回写一次,点赞这种高并发场景会将DB压垮。
改进方案:
- 接入消息队列,收到点赞消息后异步处理like_counts表
- 使用消息队列解耦后,以视频id进行聚合,之后批量写入DB,例如vid=13的视频,点赞量达到20后,对应字段直接加20,减少对DB的请求